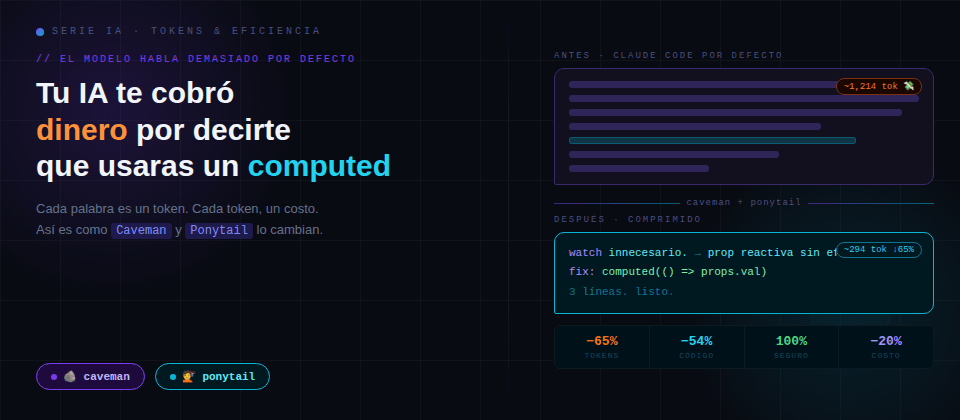
Bienvenido a este nuevo post sobre uno de los problemas más costosos y silenciosos al trabajar con IA, te a pasado que cuando abres Claude Code y le preguntas por qué tu componente de Vue está haciendo un watch innecesario cada vez que cambias una props.
Y este te responde con una introducción amable, un recordatorio de que "hay varias formas de abordar esto", dos párrafos explicando qué es la reactividad en Vue como si nunca hubieras tocado un ref() en tu vida, la solución real enterrada en el párrafo cuatro y como spoiler: era un computed de tres líneas, y un cierre tipo "¡espero que esto te haya ayudado! 😊". Estas palabras parecen muy didácticas, pero tambien te costó dinero.
Cada palabra que el modelo escribe es un token (Son la unidad de medida de todo: velocidad, precio y contexto disponible.) la gran realidad que muchos developers descubren o pretenden no darle demasiada importancia es esta: los modelos de IA tienden a hablar demasiado por defecto.
Este post es una pequeña guía para entender por qué pasa, qué consecuencias tiene, y que herramientas pueden ayudarnos como Caveman y Ponytail están cambiando esa dinámica.
¿Qué son los tokens y por que debería importarnos?
Un token es la unidad mínima con la que un modelo de lenguaje procesa texto. Aproximadamente 4 caracteres en inglés equivalen a 1 token; en español suele ser un poco más. Cada petición que haces a un modelo de IA y cada respuesta que recibes consume tokens.
Si usas agentes de IA en inglés, gastas menos tokens por defecto. No porque el modelo piense mejor en inglés, sino porque el idioma es estructuralmente más compacto.
Importancia de los tokens
- Costo. Los modelos de IA cobran por tokens consumidos. Más texto generado = más dinero gastado. En proyectos grandes o en pipelines automatizados, eso escala demasiado rápido.
- Velocidad. Generar menos tokens es, físicamente, más rápido. Una respuesta de 100 tokens llega antes que una de 1.5K.
- Ventana de contexto. Los modelos tienen un límite de cuánto "recuerdan" dentro de una conversación. Si el agente genera respuestas gigantes, la ventana se llena mucho antes, pierdes contexto previo y empieza a cometer errores o a olvidar instrucciones.
La realidad de los agentes de IA en 2026
Trabajar con agentes de IA para desarrollo de software tiene beneficios reales y comprobados. Pero también tiene fallas que la industria normalmente no menciona en sus demos:
Lo que considera que funciona bien
- Generación de código boilerplate y repetitivo
- Refactorización de funciones conocidas
- Búsqueda de bugs cuando el contexto es claro
- Documentación inicial de código existente
Lo que falla más de lo esperado
- "Inventa" APIs, métodos o librerías que no existen (alucinaciones)
- Sobre construye: pides un selector de fecha, instala una librería de 200KB
- Genera código correcto pero con 5x más líneas de las necesarias
- Los contextos largos degradan la calidad de las respuestas
Dos herramientas que atacan el problema desde ángulo distintos
🪨 Caveman "¿Por qué usar muchos tokens cuando unos pocos hacen el truco?"
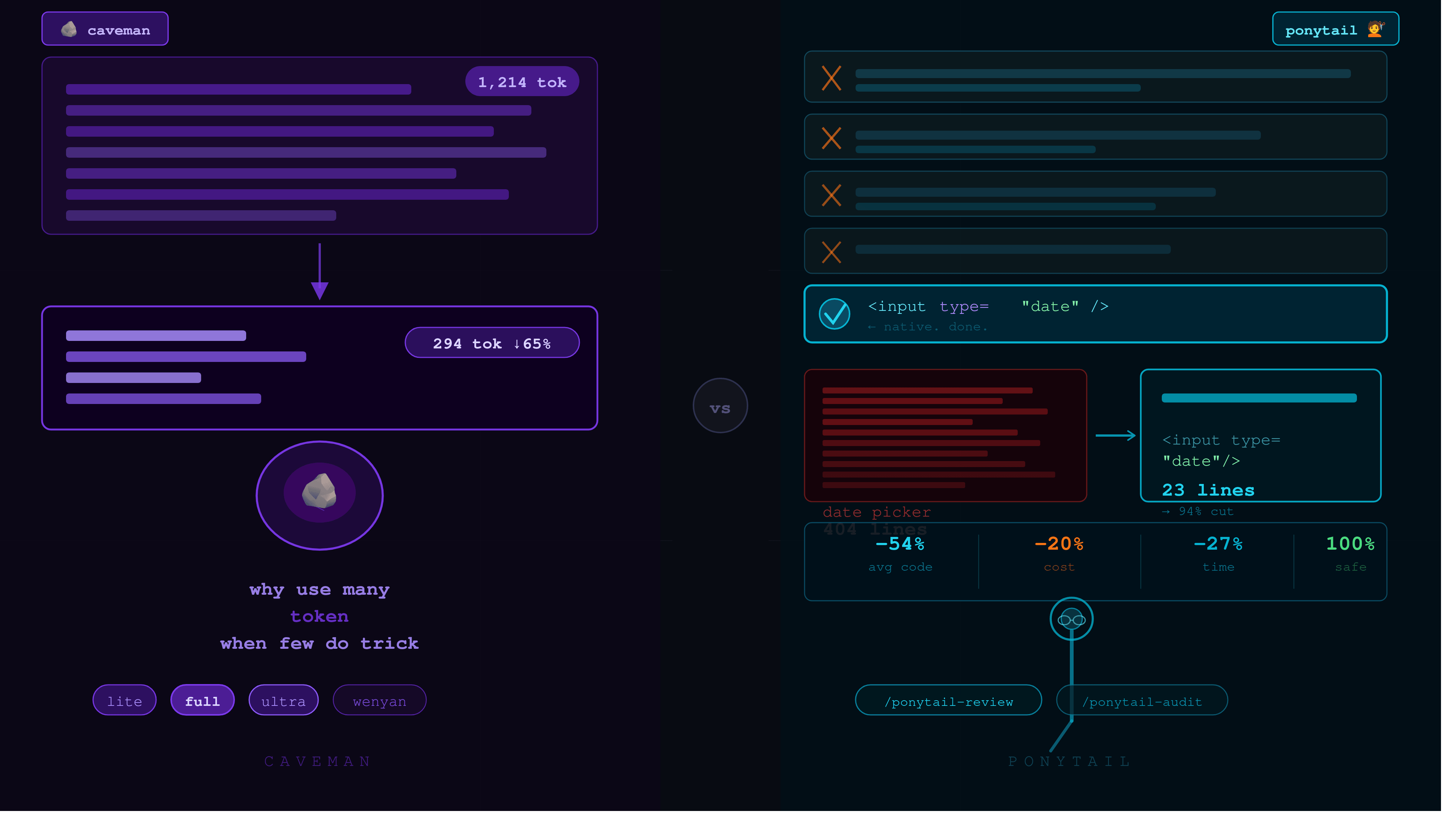
Caveman es un skill/plugin para agentes de IA (Claude Code, Codex, Cursor, Copilot y más de 30 agentes adicionales) que instruye al modelo a comunicarse de forma telegráfica, eliminando el relleno verbal sin sacrificar precisión técnica, es como que hablaras con un cavernicola. Chequea este ejemplo.
En lugar de:
"The reason your Vue component is triggering an unnecessary watch is likely because you're passing a reactive object as a prop and the watcher is tracking the entire reference instead of the specific value you care about..." (46 tokens)
Con Caveman:
"Watch tracks full ref. Use
computed(() => props.val)instead." (16 tokens)
La misma solución. 75% menos palabras.
Caveman incluye niveles de compresión o tambien conocidos como modos: (lite, full, ultra, wenyan) y herramientas adicionales como /caveman-compress para reescribir archivos de memoria del agente (como CLAUDE.md) en formato compacto, ahorrando tokens en cada sesión futura.
🐴 Ponytail "El desarrollador senior más perezoso de la sala"
Ponytail ataca un problema diferente pero relacionado: el agente no solo habla demasiado, sino que también escribe demasiado código.
Su flujo es simple: antes de escribir cualquier línea, el agente debe pasar por una escalera de decisiones:
1. ¿Esto necesita existir? → no: ni lo escribas (YAGNI)
2. ¿La stdlib lo hace? → úsala
3. ¿El navegador/plataforma lo tiene? → úsalo
4. ¿Hay una dependencia instalada? → úsala
5. ¿Cabe en una línea? → una línea
6. Solo entonces: el mínimo que funciona
El resultado en una tarea real con Claude Code sobre un componente Vue con filtro de búsqueda: 79% menos líneas de código generado, sin dependencias externas, sin lifecycle composables innecesarios, manteniendo el 100% de reactividad y comportamiento esperado.
La diferencia con simplemente pedirle "sé conciso": Ponytail preserva explícitamente la seguridad, la accesibilidad y el manejo de errores. No es código golfing, es ingeniería mínima responsable.
Ventajas y desventajas reales
Ventajas
- Reducción decostos: Menos tokens de salida = facturas más bajas o mejor gestión de tokens. En equipos que usan agentes de forma intensiva, el ahorro es significante.
- Respuestas más rápidas. El tiempo de generación es proporcional a la cantidad de tokens.
- Mayor persistencia de contextos. Al generar menos por respuesta, el agente conserva y gestiona memoria útil por más tiempo dentro de una sesión.
- Código más mantenible.
Ponytailtiende a producir soluciones más simples, que son inherentemente más fáciles de leer y modificar. - Menos librerías innecesarias. El agente deja de instalar librerías de terceros para tareas que el navegador ya resuelve con una línea nativa.
Desventajas y Limitaciones
- No es magia. Estas herramientas funcionan instruyendo al modelo vía prompts/skills. Modelos de razonamiento que invierten tokens "pensando" (como GPT-5.5 o Claude con extended thinking) pueden no reducir costos o incluso aumentarlos en casos específicos.
Cavemanpuede perder matices. En temas complejos donde la explicación detallada tiene valor (arquitectura, trade-offs de diseño), forzar brevedad puede omitir contexto importante.Ponytailno elimina alucinaciones. Reduce el código innecesario, pero no resuelve el problema de que el modelo a veces invente APIs o métodos que no existen. Eso requiere otras estrategias (RAG, contexto explícito, verificación con herramientas).- Requieren compatibilidad con el agente. Aunque ambas herramientas soportan docenas de agentes, la experiencia varía. Las instrucciones siempre activas funcionan mejor que las activadas por sesión.
- Curva de ajustes. En proyectos donde el agente necesita explicar decisiones al equipo o generar documentación detallada, el modo caveman puede estar en conflicto con esos objetivos.
Consejos prácticos (Más allá de las herramientas)
Incluso sin instalar nada, hay ajustes que puedes hacer hoy:
- Sé específico en tus prompts. "Refactoriza esta función" genera más tokens que "Extrae la lógica de validación de esta función a un método privado, sin cambiar el comportamiento externo." Cuanto más vaga es la instrucción, más extensa e imprecisa es la respuesta.
- Dale al agente el contexto exacto, no el máximo. Pegar 500 líneas de código cuando el bug está en 20 llena el contexto innecesariamente. El agente intenta "ayudar" con todo lo que ve.
- Establece restricciones explícitas. "Responde en 3 líneas o menos" o "Solo dame el código, sin explicación" son instrucciones que el modelo respeta bien.
- Prefiere herramientas nativas. Antes de pedirle al agente que instale algo, pregúntale primero si el lenguaje o el framework ya lo resuelve. Evita que el agente tome ese camino solo.
- Revisa el diff, no el archivo completo. Los agentes tienden a reescribir más de lo necesario cuando el archivo completo está en contexto. Trabaja con fragmentos cuando sea posible.
Conclusión: El agente ideal habla poco y escribe solo lo necesario
La conversación sobre IA en desarrollo de software gira casi siempre en torno a capacidades de lo que el agente puede hacer. Pero los equipos que la usan aprenden rápido que es importante es cómo lo hace, cuánto contexto consume, cuánto código genera de más, que tan directa es la respuesta.
Herramientas como Caveman y Ponytail representan una respuesta pragmática a esa realidad. No son soluciones perfectas ni reemplazan el criterio de cada developer, pero atacan problemas reales con enfoques concretos y resultados medibles.
En posts futuros vamos a profundizar en cada una por separado: cómo instalarlas, casos de uso específicos, y cómo combinarlas para diferentes workflows.
Por ahora, la pregunta que te dejo es:
¿Tu agente de IA está trabajando para ti, o estás pagando para que prepare un discurso?



